Kick-start Deep Learning with TensorFlow and Keras
This is a kick-start demo on how to run Deep Learning the ‘fast and lean way’. In other words, here I will show how to quickly have a Keras example up and running. My point was not to optimize anything, rather to get an example quickly up using information from different sources. It worked for me.
NOTE | The original German version of this article published in Entwickler.de magazine is available at Kick-start Deep Learning mit TensorFlow und Keras.
Kick-start step 1: TensorFlow
One option to implement deep learning neural networks with Python is to use the high level API Keras, which needs for example TensorFlow with Python. To install TensorFlow, make sure that you have Python 3.5 or 3.6 installed. At least today (Febr. 2nd 2018), Python 3.7 did not work. ALSO make sure you have the 64 bit version of Python installed. If you do not have the right set-up for your deep learning, you may get an error that includes:
'Could not find a version that satisfies the requirement tensorflow'.
If things went right, your console should look like this after having entered pip3 install –upgrade tensorflow (here on a Windows 7 system).
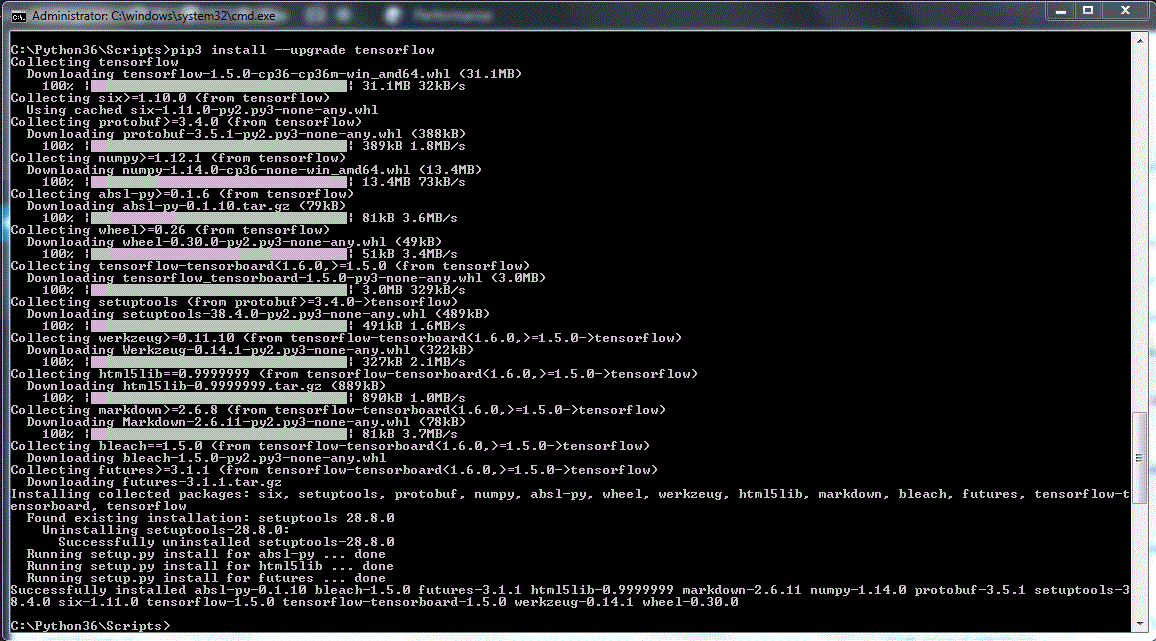
Where the path C:\Python36 is a custom setting (i.e. not the default setting).
Powershell as an administrator works well, here on a Windows 10 system:
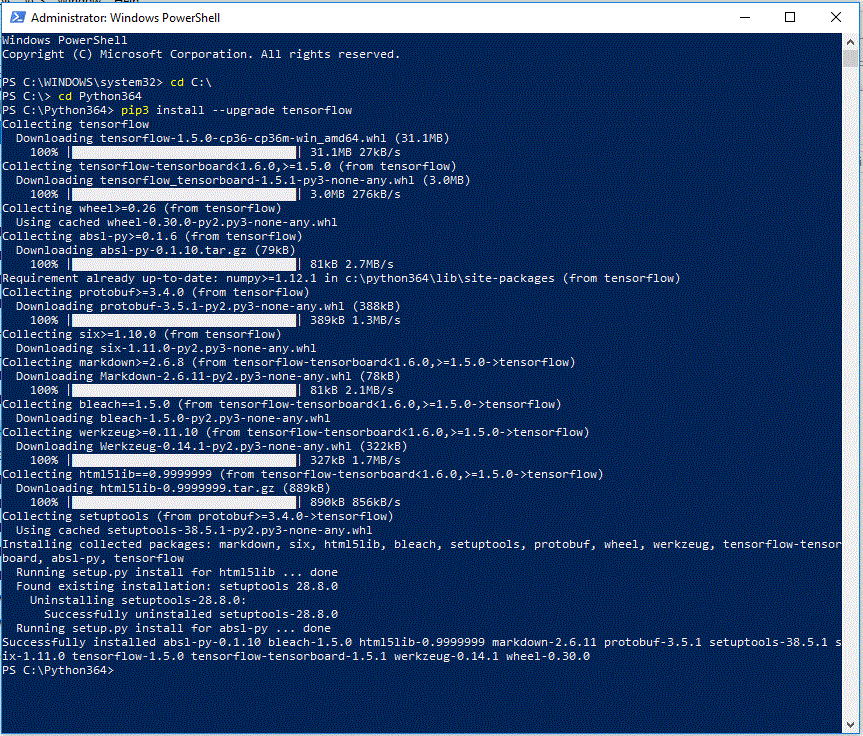
NOTE | I had already installed packages as described in https://dbc-enterprise-it-consulting.com/text-classifier/.
To check your installation, you can run the following script (from https://www.tensorflow.org/install/install_windows):
import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()
print(sess.run(hello))
Here, you might get the following or similar output:
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX
This means you do not make use of all of your CPUs features, which I ignore for now, just to get started. Later, one might want to try performance optimizations.
Sample source can be found here:
https://github.com/tensorflow/models/blob/master/samples/core/get_started/premade_estimator.py
to be used with data from here:
https://github.com/tensorflow/models/blob/master/samples/core/get_started/iris_data.py
I chose to simply copying the source into my IDE, which is PyCharm.
The iris_data also needs pandas, so you need to install from the console
pip3 install --upgrade pandas
NOTE |I also needed to install in the IDE, but that just needed a click and a little waiting.
After that you are ready to run the premade_estimator.py, which uses TensorFlow and Pandas. You get the result below:
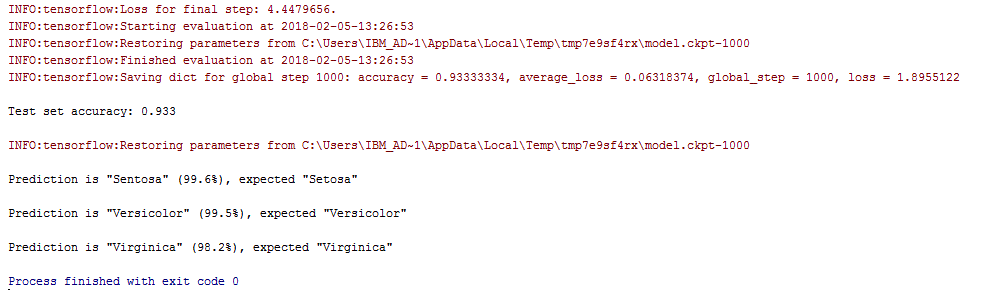
We now have trained and tested a Neural Network with two hidden layers.
Kickstart step 2: Keras
The next level of abstraction is Keras, so we do pip3 install –upgrade keras.
When installing Keras with pip install, you might get an error saying Visual Studio 14 is missing.
error: [WinError 3] The system cannot find the path specified: 'C:\\Program Files (x86)\\Microsoft Visual Studio 14.0\\VC\\PlatformSDK\\lib'
This means the windows SDK is not installed, which is then to be done from:
http://landinghub.visualstudio.com/visual-cpp-build-tools
For Keras, we can now step right into an example, just copy this source in your IDE: https://github.com/keras-team/keras/blob/master/examples/reuters_mlp.py
Save it as reuters_mlp.py and run it. First data is downloaded and prepared. There are 46 categories, 8083 training samples and 899 test samples.
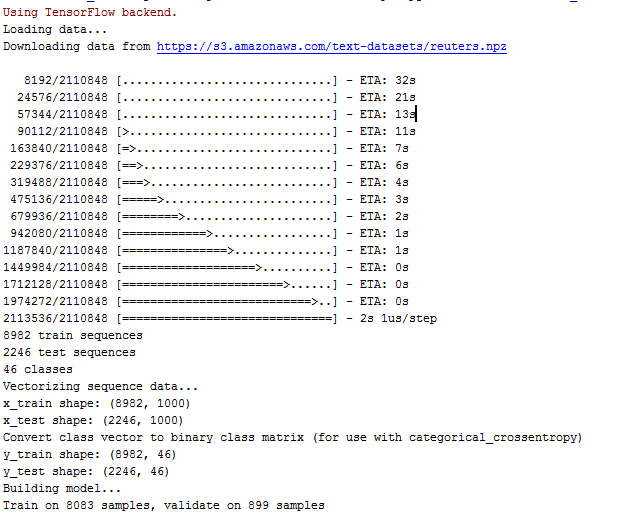
The program finishes showing the test result:
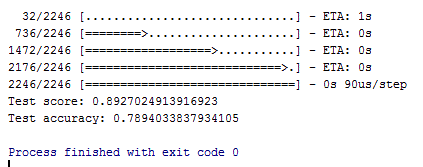
What kind of Deep Learning did we do?
After having installed Python, TensorFlow and Keras, we tried the ‘Reuters Example’ which link is provided on the Keras website. I chose this one, because I’d previously experimented with text classification and scikit-learn.
To understand what our program actually did, we checked the data that was used, which was read from https://s3.amazonaws.com/text-datasets/reuters.npz in reuters.py.
Unzipping the npz, which works with Seven Zip, we see two files: x.npy and y.npy. To find documentation about the data, one can check https://keras.io/datasets/ and search for ‘Reuters’ on that page. Here we also get the explanation: ‘each wire is encoded as a sequence of word indexes’. That means instead of sequences of words we have sequences of word IDs, which are just an index for an array.
The data used in this example are 11,228 newswires from Reuters, labeled over 46 topics. In the Pycharm debugger, we get some clue of the representation of the newswires (as xs) and the labels (as labels) .
To understand the data, we set a breakpoint in reuters.py.
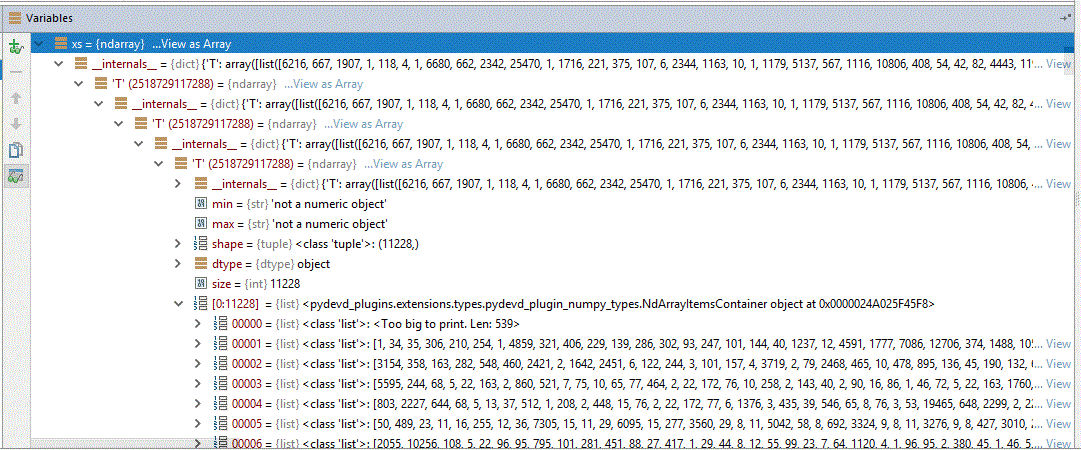
The input data (xs) to our Neural Network are 11,228 lists of numbers. Each number represents a word.
The data is then split into a training and a test set (80% training, 20% test).
In reuters_mlp.py the first data processing step is using tokenizer in order to convert the sequences of indices into a representation that makes it easier to distinguish different categories. This is achieved by concerting the sequence into a matrix of binaries.
What does the Keras tokenizer actually do?
For a better understanding what the Keras tokenizer is doing, we run a separate example with only three sentences, each just containing two words:
from keras.preprocessing.text import Tokenizer texts = ['hello, hello', 'hello world', 'good day'] tokenizer = Tokenizer(num_words=5) # number of words + 1 tokenizer.fit_on_texts(texts) print (tokenizer.word_index) my_sequences = tokenizer.texts_to_sequences(texts) print (my_sequences) print (tokenizer.sequences_to_matrix(my_sequences))
Which then generates the following output:
Using TensorFlow backend.
{'hello': 1, 'world': 2, 'good': 3, 'day': 4}
[[1, 1], [1, 2], [3, 4]]
[[0. 1. 0. 0. 0.]
[0. 1. 1. 0. 0.]
[0. 0. 0. 1. 1.]]
Here we see that:
- Each distinctive word has a unique index
- The sequence could be reconverted into the original text with a lookup in word_index
- The binaries just show whether a word exists in one or more times in a sentence, but does not reflect how many times
- Overlaps (same words) in sentences are shown as ‘1’ at same position in the vectors (rows of the matrix).
The neural network part
Going back to the reuters_mlp.py, after line 40, one sees the construction, training and testing of the neural network. All this happens in 20 lines of code – before that, it’s all about preparing the data. The preparation is critical: important features can be lost, or one may choose representations unsuitable for the classification algorithm. The data material determines the most suitable pre-processing, i,e., how relevant is the frequency of individual words. We’ve used the neural network here as a black box for classification. Various algorithms were applicable. I’ll carry on tinkering with and enjoying further experiments and possible applications.
Andreas Bühlmeier, PhD.
February 2018
All rights reserved. See also Impressum / Legal notice.